



Following the Fastly outage, Nick Rockwell, Fastly’s Senior VP of Engineering and Infrastructure, shared an update on their blog [1] identifying the root cause as an “undiscovered software bug” that was “triggered by a valid customer configuration change”. Whilst it is reassuring to know that no nefarious actor caused the outage, incidents such as this serve as an important reminder to ensure that QA processes are robust, especially when dealing with infrastructure that has such a wide-reaching impact.
Commencing just before 1000hrs UTC on June 8, 2021, widespread reports of high-profile websites being unavailable began to surface with visitors to these sites receiving ominous looking error messages (Figure 1).
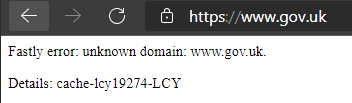
Figure 1 – Example outage message ‘gov.uk‘
Initially, many of these error messages returned a HTTP error ‘503’, advising the user that the service is unavailable, and these originated from a ‘Varnish cache server’ HTTP accelerator that was attempting to serve the intended content.
It is understood that these Varnish cache servers are utilized by the cloud services provider Fastly in their content delivery network (CDN), a fact subsequently proven by the Fastly ‘unknown domain’ errors, and therefore indicating that this major outage was caused by some issue in their CDN.
Testing access from multiple geographic locations confirmed that this issue was not specific to any one region or group of cache servers, consistent with the worldwide reports and the origin of many of the affected websites.
Whilst a reason for the outage was not initially shared, causing some to be concerned of foul-play, Fastly [2] subsequently identified and fixed a service configuration issue within an hour (Figure 2).
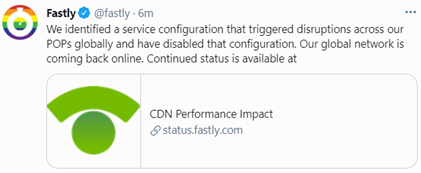
Figure 2 – Fastly’s initial explanation
Cyberint will continue to monitor the situation and, like many, keenly await the publication of a post-mortem report by Fastly.
Although many major websites are working around the issues arising from the Fastly CDN outage, some services may remain inaccessible or appear in some ‘degraded’ state.
For example, Amazon and Twitter both appeared to have image display and/or visual styles affected by the outage (Figure 3).
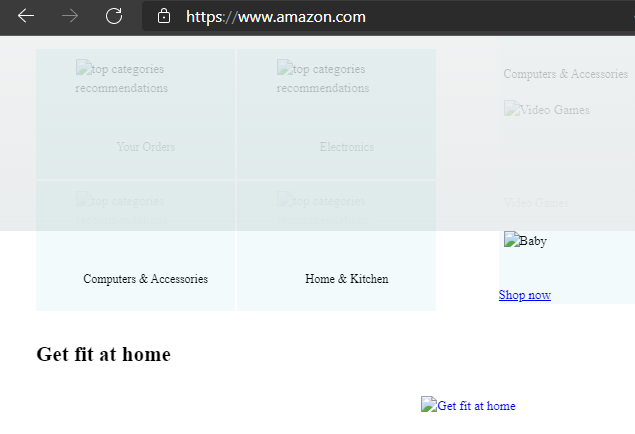
Figure 3 – Amazon.com homepage with broken image links and styles
Whilst not an exhaustive list, major websites suffering an outage due to this incident included:
As of 1057hrs UTC, Fastly report that they have identified and fixed [3] the suspected configuration issue and their customers are advised that they may experience increased load as the services return (Figure 4).
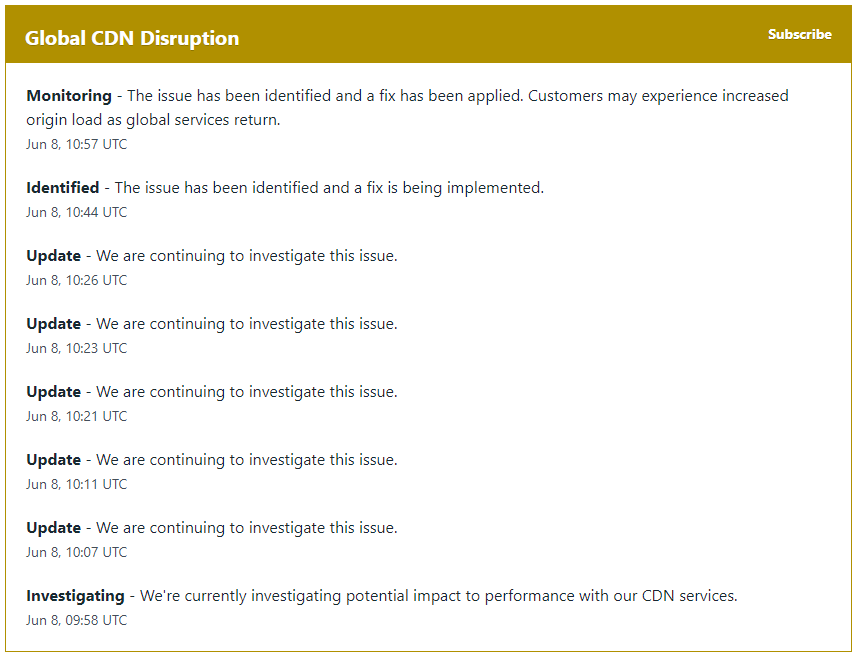
Figure 4 – Fastly Network Status
[1] https://www.fastly.com/blog/summary-of-june-8-outage
[2] https://twitter.com/fastly/status/1402221348659814411?s=20